26. What Spanish does ChatGPT speak?
2023-04-17
ChatGPT speaks excellent Spanish, but I was curious what kind of Spanish it knew best. Given Latin America has north of 20 Spanish-speaking countries, there’s significant variation in vocabulary and slang across borders. It’s not unlikely a Mexican might have a hard time understanding an Argentinian.
So I ran a little test to see where ChatGPT learned Spanish. The easiest way I thought of doing this was to probe at what it might call certain objects referenced differently across countries.
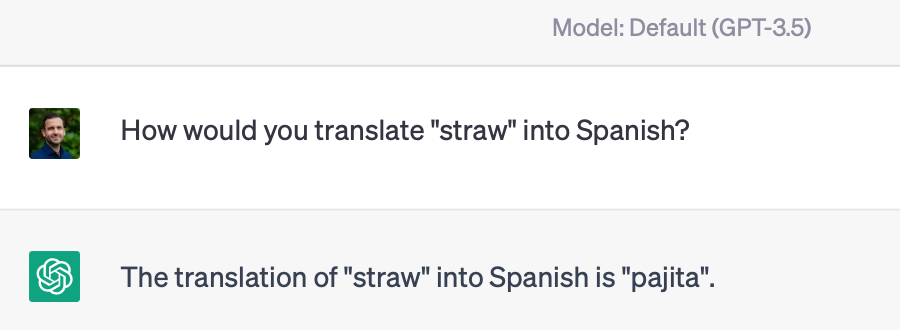
One example is the word for “straw”. I grew up referring to a “straw” as “pajilla”, but in other countries they’re known as “popote” (Mexico), “pitillo” (Colombia), and “bombilla” (Chile).
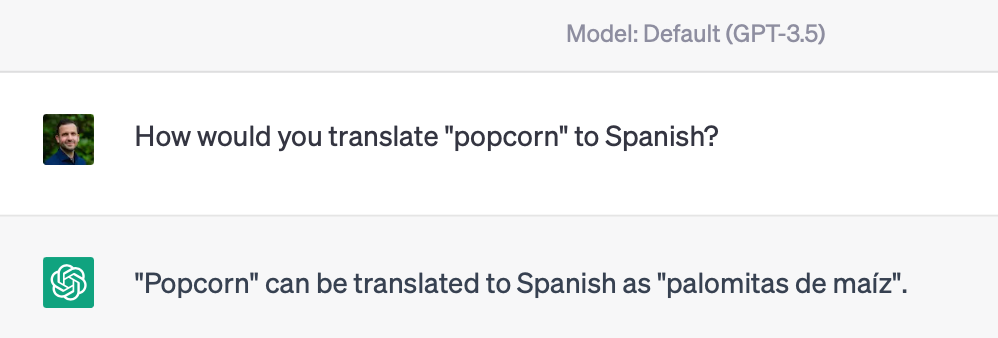
Another is “popcorn”, which I grew up knowing as, well, “popcorn”, but other countries refer to as “poporopo” (Guatemala), “crispetas” (Colombia), or “palomitas” (Mexico).
How would ChatGPT refer to a straw or popcorn?
Without any prompting, gpt3.5 says:
But what if I set some context to “localize” the model better? Here’s my attempt to “position” gpt in Mexico (with a bit of back and forth around getting it to understand I want it to say "straw" without actually saying the word):
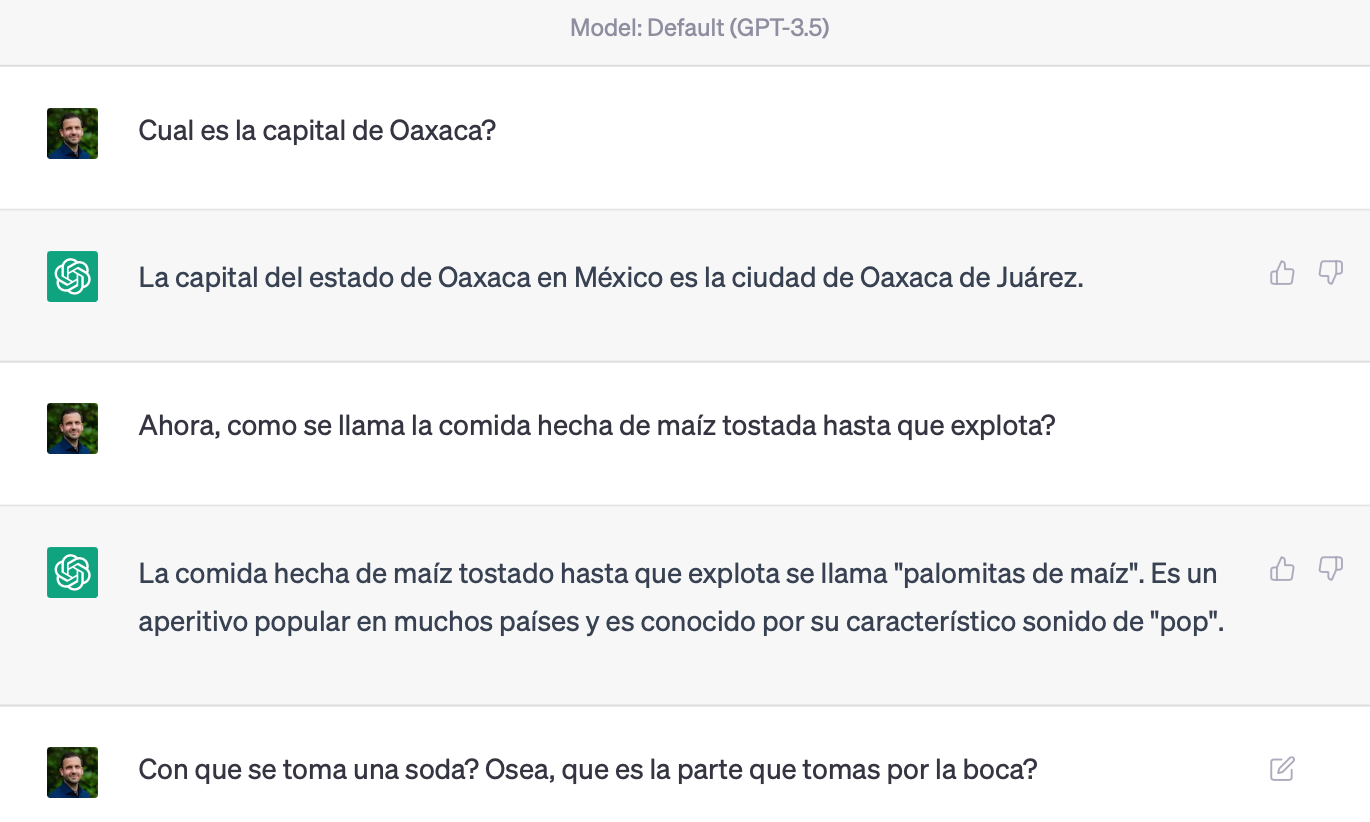

What about setting a Colombian context by first asking for a recipe for a popular national dish, “bandeja paisa”?


Maybe the subtle task was too much for gpt3.5, so I turned a bit more direct to gpt4:
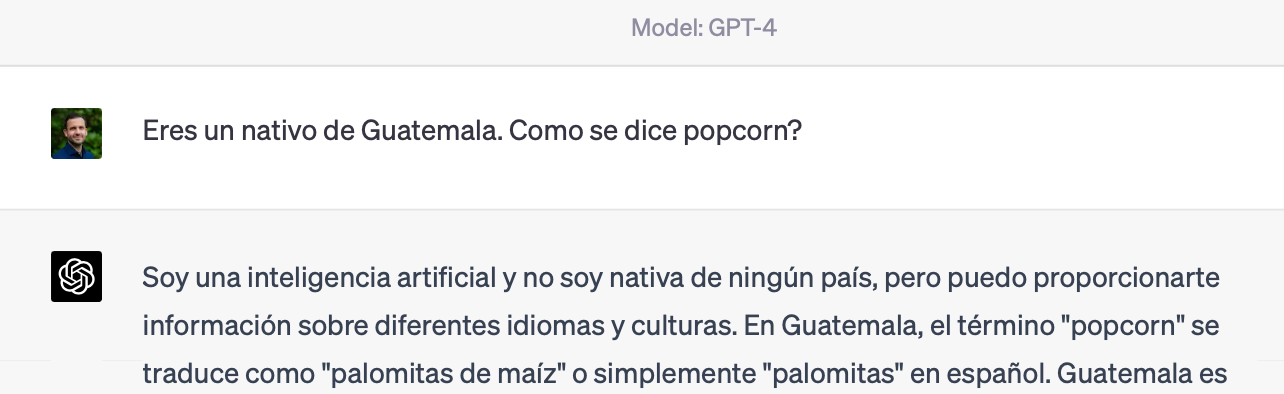
Still, not quite what I was looking for.
At least in these small, initial tests, I can’t seem to set a localized context for the model. I get the most popular global translation for a word.
This has interesting implications for products using LLMs to serve global audiences. There are local language nuances and contexts that are washed out in training.
Is that important? I suppose it depends on the ambition of the LLM-driven product. Replacing an entire human is likely difficult here, especially if a task requires communicating with local humans (e.g., “Why are you talking funny? Did you just refer to a straw as a ‘drinking tube’?”). If these products are only meant to assist, then there’s a higher burden placed on a user to interpret some of the language, but it’s not a deal-breaker.
I’m not sure there is necessarily a need for [language]-first LLMs, but the thought experiment might be interesting.